 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrthogonal Negative Guidance in Attention Feature Space for Text-to-Image Generation
May 28, 2026Text-to-image (T2I) models have become increasingly capable of generating high-quality images. Yet, enforcing the explicit absence of a specified object or attribute remains a fundamentally challenging problem. Existing approaches, including prompt negation, post-hoc editing, and negative guidance, remain insufficient for explicit concept suppression, often failing to remove the target concept or degrading overall image quality. To this end, we propose Orthogonal Negative Guidance in attention feature space, a training-free method that operates in the attention output space of MM-DiT-based T2I transformers. Our method orthogonalizes negative-prompt attention features with respect to positive-prompt features and subtracts only the orthogonal component, suppressing unwanted concepts while preserving desired semantics. Experiments on FLUX-dev and FLUX-schnell show that our method achieves favorable trade-offs between concept suppression, prompt alignment, and image quality. In human evaluation, our method outperforms the second-best baseline by 18.78%. We further show that our method supports multi-concept suppression and adjustable concept suppression.
When Confidence Misleads: Suffix Anchoring and Anchor-Proximity Confidence Modulation for Diffusion Language Models
May 27, 2026Diffusion language models decode text by iteratively denoising masked token sequences, making the choice of which positions to decode a central inference-time decision. Most training-free decoding strategies use model confidence for position selection, assuming that high-confidence positions are ready to be decoded. In this work, we revisit this assumption by studying when confidence misleads fully non-autoregressive (fully non-AR) decoding. EOT tokens can receive high confidence and cause incomplete generation; inserting a suffix anchor can mitigate this issue but introduces local overconfidence near the anchor, causing anchor-adjacent tokens to be decoded too early. To address these issues, we propose Suffix-Anchored Confidence Modulation, a simple training-free method that inserts a short suffix anchor to encourage response completion and modulates confidence near the anchor according to decoding progress. This preserves the response-completion benefit of suffix anchoring while reducing premature decoding of anchor-adjacent tokens. Across text-only reasoning, vision-language reasoning, and code-generation benchmarks, our method consistently improves confidence-based fully non-AR decoding, outperforms explicit EOT suppression, and preserves the parallel decoding advantage of fully non-AR generation.
Selective Aggregation of Attention Maps Improves Diffusion-Based Visual Interpretation
Apr 07, 2026Numerous studies on text-to-image (T2I) generative models have utilized cross-attention maps to boost application performance and interpret model behavior. However, the distinct characteristics of attention maps from different attention heads remain relatively underexplored. In this study, we show that selectively aggregating cross-attention maps from heads most relevant to a target concept can improve visual interpretability. Compared to the diffusion-based segmentation method DAAM, our approach achieves higher mean IoU scores. We also find that the most relevant heads capture concept-specific features more accurately than the least relevant ones, and that selective aggregation helps diagnose prompt misinterpretations. These findings suggest that attention head selection offers a promising direction for improving the interpretability and controllability of T2I generation.
DOS: Directional Object Separation in Text Embeddings for Multi-Object Image Generation
Oct 16, 2025



Recent progress in text-to-image (T2I) generative models has led to significant improvements in generating high-quality images aligned with text prompts. However, these models still struggle with prompts involving multiple objects, often resulting in object neglect or object mixing. Through extensive studies, we identify four problematic scenarios, Similar Shapes, Similar Textures, Dissimilar Background Biases, and Many Objects, where inter-object relationships frequently lead to such failures. Motivated by two key observations about CLIP embeddings, we propose DOS (Directional Object Separation), a method that modifies three types of CLIP text embeddings before passing them into text-to-image models. Experimental results show that DOS consistently improves the success rate of multi-object image generation and reduces object mixing. In human evaluations, DOS significantly outperforms four competing methods, receiving 26.24%-43.04% more votes across four benchmarks. These results highlight DOS as a practical and effective solution for improving multi-object image generation.
Soft Injection of Task Embeddings Outperforms Prompt-Based In-Context Learning
Jul 28, 2025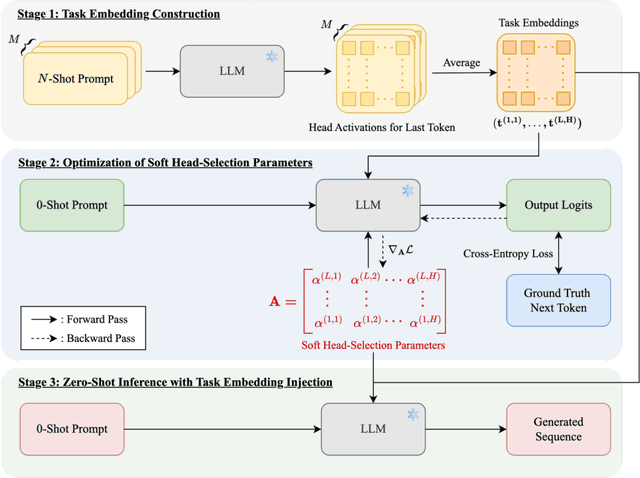
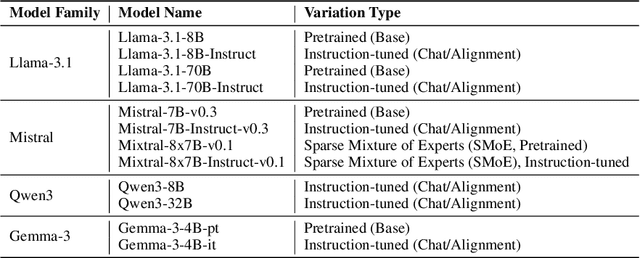
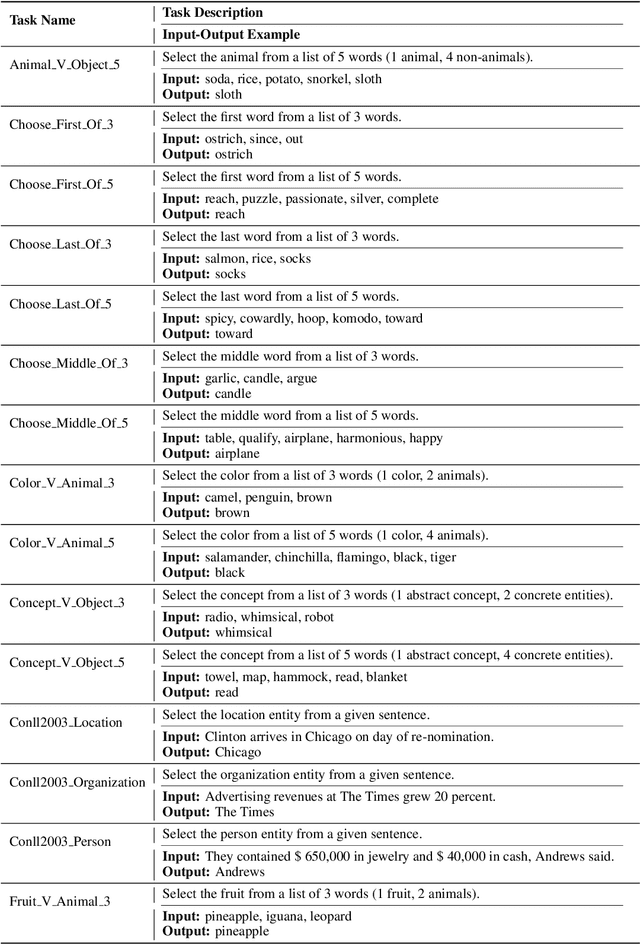
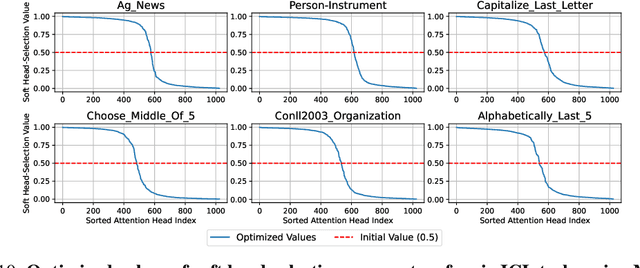
In-Context Learning (ICL) enables Large Language Models (LLMs) to perform tasks by conditioning on input-output examples in the prompt, without requiring any update in model parameters. While widely adopted, it remains unclear whether prompting with multiple examples is the most effective and efficient way to convey task information. In this work, we propose Soft Injection of task embeddings. The task embeddings are constructed only once using few-shot ICL prompts and repeatedly used during inference. Soft injection is performed by softly mixing task embeddings with attention head activations using pre-optimized mixing parameters, referred to as soft head-selection parameters. This method not only allows a desired task to be performed without in-prompt demonstrations but also significantly outperforms existing ICL approaches while reducing memory usage and compute cost at inference time. An extensive evaluation is performed across 57 tasks and 12 LLMs, spanning four model families of sizes from 4B to 70B. Averaged across 57 tasks, our method outperforms 10-shot ICL by 10.1%-13.9% across 12 LLMs. Additional analyses show that our method also serves as an insightful tool for analyzing task-relevant roles of attention heads, revealing that task-relevant head positions selected by our method transfer across similar tasks but not across dissimilar ones -- underscoring the task-specific nature of head functionality. Our soft injection method opens a new paradigm for reducing prompt length and improving task performance by shifting task conditioning from the prompt space to the activation space.
ReFlex: Text-Guided Editing of Real Images in Rectified Flow via Mid-Step Feature Extraction and Attention Adaptation
Jul 02, 2025



Rectified Flow text-to-image models surpass diffusion models in image quality and text alignment, but adapting ReFlow for real-image editing remains challenging. We propose a new real-image editing method for ReFlow by analyzing the intermediate representations of multimodal transformer blocks and identifying three key features. To extract these features from real images with sufficient structural preservation, we leverage mid-step latent, which is inverted only up to the mid-step. We then adapt attention during injection to improve editability and enhance alignment to the target text. Our method is training-free, requires no user-provided mask, and can be applied even without a source prompt. Extensive experiments on two benchmarks with nine baselines demonstrate its superior performance over prior methods, further validated by human evaluations confirming a strong user preference for our approach.
Task-Specific Preconditioner for Cross-Domain Few-Shot Learning
Dec 20, 2024



Cross-Domain Few-Shot Learning~(CDFSL) methods typically parameterize models with task-agnostic and task-specific parameters. To adapt task-specific parameters, recent approaches have utilized fixed optimization strategies, despite their potential sub-optimality across varying domains or target tasks. To address this issue, we propose a novel adaptation mechanism called Task-Specific Preconditioned gradient descent~(TSP). Our method first meta-learns Domain-Specific Preconditioners~(DSPs) that capture the characteristics of each meta-training domain, which are then linearly combined using task-coefficients to form the Task-Specific Preconditioner. The preconditioner is applied to gradient descent, making the optimization adaptive to the target task. We constrain our preconditioners to be positive definite, guiding the preconditioned gradient toward the direction of steepest descent. Empirical evaluations on the Meta-Dataset show that TSP achieves state-of-the-art performance across diverse experimental scenarios.
Cross-Attention Head Position Patterns Can Align with Human Visual Concepts in Text-to-Image Generative Models
Dec 03, 2024



Recent text-to-image diffusion models leverage cross-attention layers, which have been effectively utilized to enhance a range of visual generative tasks. However, our understanding of cross-attention layers remains somewhat limited. In this study, we present a method for constructing Head Relevance Vectors (HRVs) that align with useful visual concepts. An HRV for a given visual concept is a vector with a length equal to the total number of cross-attention heads, where each element represents the importance of the corresponding head for the given visual concept. We develop and employ an ordered weakening analysis to demonstrate the effectiveness of HRVs as interpretable features. To demonstrate the utility of HRVs, we propose concept strengthening and concept adjusting methods and apply them to enhance three visual generative tasks. We show that misinterpretations of polysemous words in image generation can be corrected in most cases, five challenging attributes in image editing can be successfully modified, and catastrophic neglect in multi-concept generation can be mitigated. Overall, our work provides an advancement in understanding cross-attention layers and introduces new approaches for fine-controlling these layers at the head level.
A Benchmark Suite for Evaluating Neural Mutual Information Estimators on Unstructured Datasets
Oct 14, 2024



Mutual Information (MI) is a fundamental metric for quantifying dependency between two random variables. When we can access only the samples, but not the underlying distribution functions, we can evaluate MI using sample-based estimators. Assessment of such MI estimators, however, has almost always relied on analytical datasets including Gaussian multivariates. Such datasets allow analytical calculations of the true MI values, but they are limited in that they do not reflect the complexities of real-world datasets. This study introduces a comprehensive benchmark suite for evaluating neural MI estimators on unstructured datasets, specifically focusing on images and texts. By leveraging same-class sampling for positive pairing and introducing a binary symmetric channel trick, we show that we can accurately manipulate true MI values of real-world datasets. Using the benchmark suite, we investigate seven challenging scenarios, shedding light on the reliability of neural MI estimators for unstructured datasets.
Towards a Better Evaluation of Out-of-Domain Generalization
Jun 02, 2024The objective of Domain Generalization (DG) is to devise algorithms and models capable of achieving high performance on previously unseen test distributions. In the pursuit of this objective, average measure has been employed as the prevalent measure for evaluating models and comparing algorithms in the existing DG studies. Despite its significance, a comprehensive exploration of the average measure has been lacking and its suitability in approximating the true domain generalization performance has been questionable. In this study, we carefully investigate the limitations inherent in the average measure and propose worst+gap measure as a robust alternative. We establish theoretical grounds of the proposed measure by deriving two theorems starting from two different assumptions. We conduct extensive experimental investigations to compare the proposed worst+gap measure with the conventional average measure. Given the indispensable need to access the true DG performance for studying measures, we modify five existing datasets to come up with SR-CMNIST, C-Cats&Dogs, L-CIFAR10, PACS-corrupted, and VLCS-corrupted datasets. The experiment results unveil an inferior performance of the average measure in approximating the true DG performance and confirm the robustness of the theoretically supported worst+gap measure.